Howto TRR379
The is the documentation site of the Collaborative Research Center / Transregio 379: Neuropsychobiology of Aggression (TRR379).
Select any topic from the menu or search this site for information.
The is the documentation site of the Collaborative Research Center / Transregio 379: Neuropsychobiology of Aggression (TRR379).
Select any topic from the menu or search this site for information.
The Q02 project operates a network of RDM-related services supporting the TRR379. They are described in more detail in the following sections.
graph TB;
subgraph Central services
C1[("Collaboration portal<br>hub.trr379.de<br> 🔐")]
C2{{"Cohort search<br>nb-query.trr379.de<br> 🔐"}}
C3(Main website<br>www.trr379.de)
C4("Data catalog<br>data.trr379.de")
C5[("Knowledge pool<br>pool.trr379.de<br> 🔐")]
C6("Documentation<br>docs.trr379.de")
C7("Data models<br>concepts.trr379.de")
end
U1(("General Public"))
U2(("TRR379 member"))
C1 --> C3
C1 --> C6
C1 --> C7
C1 --> U2
C2 --> U2
C3 --> U1
C4 --> U1
C5 --> C1
C5 --> C2
C5 --> C4
C5 --> C3
C5 --> U1
C5 --> U2
C6 --> U2
C7 --> C5
U2 --> C1
U2 --> C5
The website status.trr379.de provides a central monitor for TRR379 services. In case of an outage (or a suspected outage), this site can be used to look for already known issues, or to report new ones.
Service outages and recoveries are also available as push notifications. Contact trr379@lists.fz-juelich.de to get access. A notification is pushed when a service failure is detected for more than two consecutive tests (typically a 10min interval).
This is the main website of the TRR379.
This website is not just a public-facing view on the consortium. It is specifically built to be the core component of the metadata concept of TRR379. It provides a collection of canonical definitions of entities essential for the function of TRR379. Such entities include
Any such entity has a dedicated page on the website, with a stable URL that serves as a URI for that entity. As such, these URLs can be used in any TRR379-related metadata to declare relationships to TRR379 entities, for example, the authorship of a publication, the origin project of a data release, etc.
The website is built with the static site generator Hugo. It capitalized on its taxonomy feature. Any page on the site is built from a metadata record. For Hugo, this metadata is presented in the form of a page’s front matter. However, these metadata may themselves be generated from the result of a database query.
Here is an example record for TRR379 spokesperson Ute Habel:
From this information, the page that identifies and describes Ute
Habel as a spokesperson is
generated. It also links and references her record on the respective pages for
projects, sites, and roles she is associated with. Consequently, the URL
https://www.trr379.de/contributors/ute-habel/ can serve as a URI for Ute Habel
within the TRR379 metadata. Moreover, ute-habel is a unique identifier for her
as a contributor to TRR379.
While other special-purpose identification systems exist (e.g.,
https://orcid.org for academics), this approach is automatically applicable to
any concept and entity relevant to TRR379. Including roles, data acquisition
methods, instruments, etc. The domain root trr379.de represents a unique
namespace to define and reference any required entities. This enables a timely
and unencumbered development of a metadata concept for TRR379, without
hindering alignment with and mapping to more global efforts and initiatives.
Structured metadata is rendered to an HTML website with Hugo using a template. This approach separates the information from its presentation.
The look of the website can be altered by adjusting the template, or switching to a different template entirely. This requires familiarity with Hugo and its templating mechanism.
At present, the congo template is used.
https://hub.trr379.de is the central (data) collaboration site of the consortium. It runs an enhanced variant of the Forgejo software that is designed for maximum interoperability with the RDM solution DataLad.
The main difference to the Gitlab solution – that is also employed by TRR379 for internal purposes – is the ability to also host arbitrarily large data on the same site. The integration with the git-annex software makes it ideal for the federated, multi-site nature of TRR379. The full software-stack is free and open source software, and can be deployed at any collaborating site with minimal effort. This aspect is essential for supporting the decentralized RDM approach of the TRR.
Any contributor can have an account on the central hub. Please contact Michael Hanke to get set up.
TRR379 uses a dedicated CalDAV server at https://cal.trr379.de. This service can be used to host any number of online calendars. Individual calendars can be configured to be publicly accessible, or only for internal (authenticated) consumption.
Any number of non-public calendars can be created and shared with specific audiences. This can be useful to coordinate data acquisition sessions, organize room bookings, or schedule slots for internal meetings and events.
Contact the management team to request a dedicated calendar.
All public calenders are available via CalDAV URL and can be included in any calendar solution, such as Google calendar.
The URLs follow the pattern https://cal.trr379.de/public/<name>,
where <name> is the calendar name, as stated in the list below. For the
events calendar this is https://cal.trr379.de/public/events.
For use with Google calendar, replace https:// with webcal://. For example,
the events calendar can be added to Google calender with the URL
webcal://cal.trr379.de/public/events.
Available public calendars:
events: General TRR379 events [preview]https://data.trr379.de hosts the data catalog of the TTR379. This site is currently work in progress, and will be published once the project has started to accumulate data.
A data catalog is a website that displays and organises information that you provide about your collected datasets. The purpose of a catalog is to make data more FAIR, specifcally more findable, even if they are access restricted. The catalog further encourages collaboration between partner sites. If all partners share a common data catalog which showcases their respective collected datasets, partners can more easily engage in potential collaborations with each other as they can see what data has already been collected at each site.
The data catalog only makes metadata (i.e. descriptive fields about your dataset) openly available, there is no need to make the actual data file content publicly accessible. In other words, you do not need to upload sensitive data (or publicly available data, for that matter) anywhere in order for the dataset to be part of the catalog, just metadata. Providing full access to a dataset, or merely to a limited description about a dataset is entirely within your control. If a partner wishes to pursue a collaboration regarding a certain dataset, that partner will still need to follow the existing institutional routes of requesting access to your dataset. You have FULL control over what information is displayed in the catalog, and if you want the data files to be publicly accessible or not.
Catalog sources follow a specific design and structure.
The main source of metadata for the data catalog is the DataLad dataset at ./data, also referred to as the catalog superdataset or the catalog homepage dataset.
The idea is that this superdataset acts as a container for the metadata of all new datasets that should be represented in the catalog.
In a typical catalog source repository, you will find the following structure:
./catalog - this is where the data catalog sources live - the live catalog site serves this directory
./code - this directory contains scripts that are used for catalog updates
./data - this is a DataLad subdataset of the current data-catalog dataset/repo - its origin is at: abcd-j/data - it functions as the superdataset for all datasets rendered in the catalog, i.e. it is the homepage of the catalog
./docs - documentation sources - contains documentation for catalog users and contributors
./inputs - input files used during catalog creation, updates, and testing
The knowledge pooling tool is a system used for aggregating information on research progress and outputs across TRR379 partner sites and projects. It comprises a web UI for manually submitting, editing, and browsing information, and an API for programmatic submission and retrieval.
The current (generation v0) tool can be accessed at:
For technical information on the knowledge pooling tool and its data and privacy policy, visit:
For information on using the knowledge pooling tool, see the Use the knowledge pooling tool How to pages.
https://nb-query.trr379.de hosts the central NeuroBagel query interface of the TRR379. With this solution, data availability can be queried dynamically, to faciliate data access requests.
NeuroBagel supports federated queries and is therefore ideally suited for the decentralized research data management approach of TRR379.
https://concepts.trr379.de hosts resources and documentation on the metadata models driving the research data management procedures of TRR379.
https://docs.trr379.de (this site) is the main documentation source for the TRR379. It offers information on facilities and procedures.
All PhD students funded by the TRR379 participate in its Research Training Group.
This involves certain obligations, of which you can find an overview below:
Send a note of absence (via email) in case of illness | traveling for work | holidays | non-self-arranged meetings*
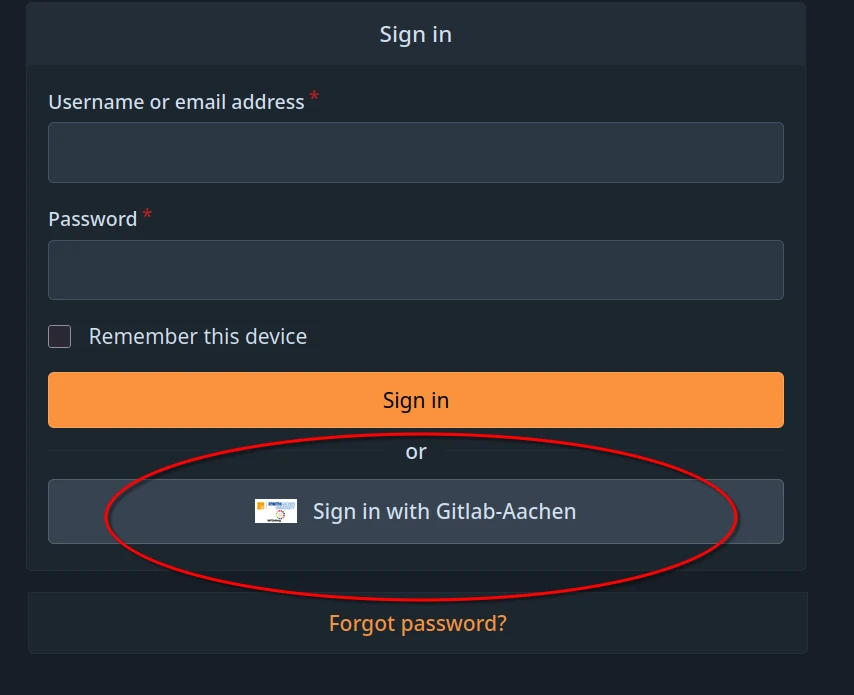
For working with the TRR379 collaboration platform an account is required. You can either request an account manually, or sign in using “GitLab Aachen” single Sign-On (SSO).
In order to sign in with Gitlab-Aachen, visit the TRR379 collaboration platform and click Sign in with Gitlab-Aachen on the login page. Login using your preferred identity provider (i.e., GitHub or your affiliated organization via DFN-AAI SSO). Follow the on-screen instructions to activate your account.
Make sure to visit the confirmation link that will be sent to the email address associated with the account.
Upon confirmation the account will be in a restricted state for security reasons. It will allow for login, but will not give read or write access to any resources. New accounts will then be assigned to the respective projects. To expedite the process, please email trr379@lists.fz-juelich.de with a list of resources you need read and/or write access too (i.e., the knowledge pool, the main website, data hosting).
In order to obtain an account manually, please email trr379@lists.fz-juelich.de. Please email from an institutional email, and CC the respective TRR379 project lead. In the email, please mention any projects and/or organizations you require read or write access to.
Please note that a manual request will not allow for using your institutional single-sign-on (SSO).
The main TRR379 website is automatically rendered with Hugo. The website sources are hosted on the TRR379 collaboration hub in a repository under the Q04 project organization.
This repository is a DataLad dataset, the same technology that is used for research data management in the TRR379.
The repository README contains instruction on how to obtain a clone of the website for working on it, and testing it locally.
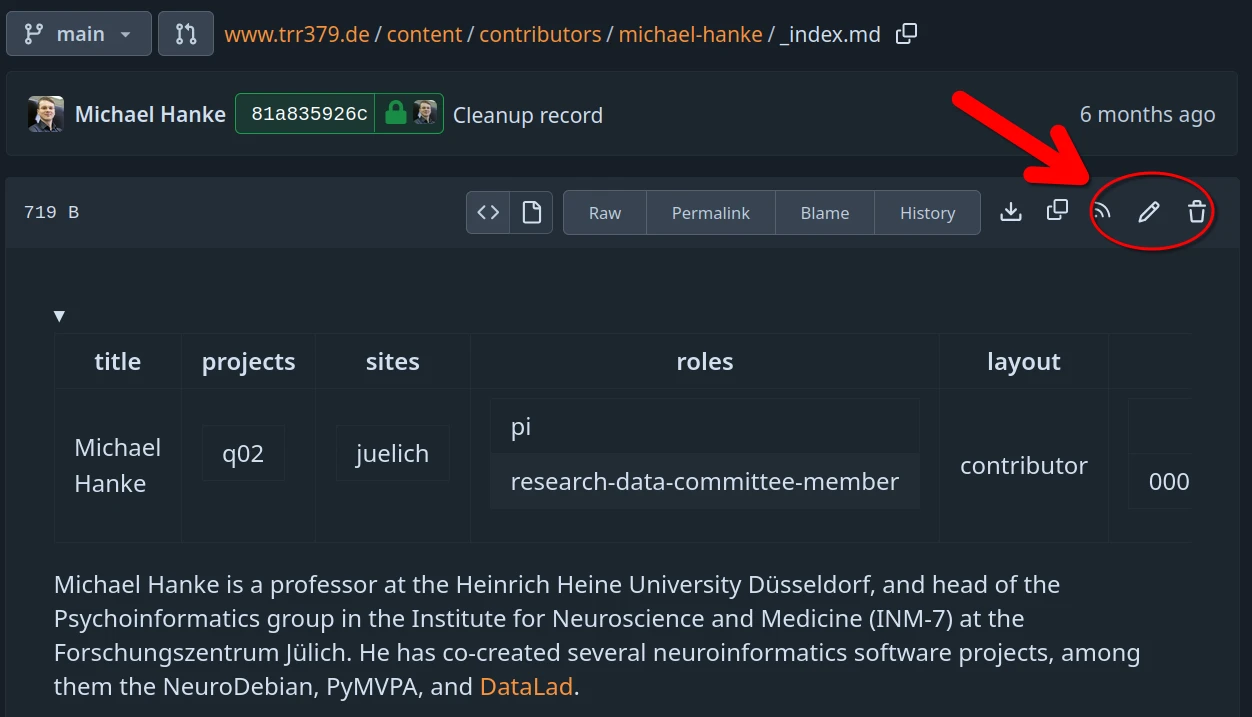
Alternatively, small edits can be done on the collaboration hub directly. The content of all pages can be browsed at https://hub.trr379.de/q04/www.trr379.de/src/branch/main/content.
Each page provides an “edit button” that enables editing content directly in the browser. The following screenshot show this button for the source file of the personal profile of Michael Hanke.
Once a change has been submitted, it is not reflected on the website immediately. All changes are reviewed and possibly adjusted by the website editor team of the Q04 project.
The knowledge pooling tool is a platform for collecting, curating, and sharing structured information about research activities, outputs, and contributors across TRR379 projects and institutions. It includes:
The following workflows provide step-by-step guidance for working with the knowledge pooling tool:
This guide explains how to get started with the knowledge pooling tool, including how to access the system, authenticate as a contributor, and prepare for submitting or curating records. The focus of these steps differ depending on your role:
Access to the knowledge pooling tool is managed using tokens and Forgejo teams. Forgejo-based authentication ensures that permissions are linked to existing institutional or project accounts. Tokens are used to identify users with interacting with the API or web UI.
Each user can hold different roles, such as:
To report and access records using the knowledge pooling tool, you must have read and write access to the protected collection of the pooling tool on the TRR379 collaboration platform.
You must be a member of both:
To confirm your team memberships, first sign into the TRR379 collaboration platform (see also How to get a Hub account and log in), then click the links above to see the team members. If you are unable to see the repository, team member list, or if your username is not listed, see below how to request access. Otherwise, proceed to generate a personal access token.
protected team(s)If you are not yet a member of the metadata-pool-read-protected and/or metadata-pool-write-protected team(s), please email trr379@lists.fz-juelich.de with a request to be added. Please send the email from an institutional email with the respective TRR379 project lead in CC.
Reading and writing records into the knowledge pooling tool requires a token linked to your Forgejo account.
From your collaboration platform account, navigate to Profile and settings > Settings > Applications > Generate new token.
Name the token, choose All for the repository and organization access, and click Select permissions to list further permissions; the token needs to have user:Read and organization:Read permissions. Click Generate token once all permissions are set.
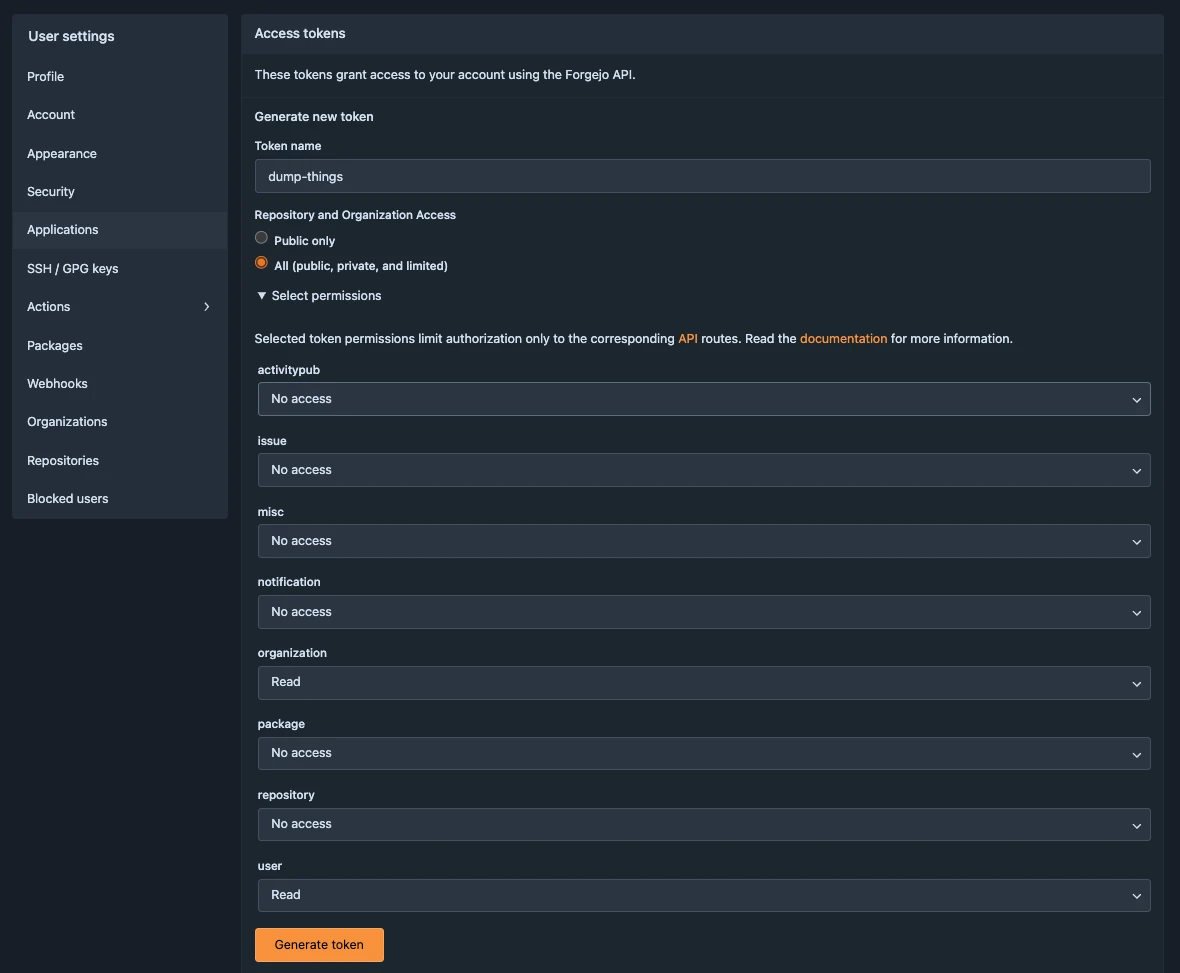
Copy the generated value and store your token securely; it will be used to authenticate your submission through the web UI and in API calls.
Treat your token like a password. Do not share it publicly.
You can verify that your token works using a simple API request:
If the token is valid, this command will return a (potentially empty) list of entries.
If the token is invalid, it will return an invalid token error, together with helpful information what may be wrong (e.g., wrong scopes).
Once your token is working and you have confirmed your access, you can proceed to the general usage guide and relevant workflows for instructions on how to enter or retrieve research metadata and outputs through the knowledge pooling tool.
This section will describe how to configure the knowledge pooling tool from a management perspective, including:
protected) and configuring the backend API (see also the Dump Things Service documentation)This guide explains how to use the knowledge pooling tool’s shacl-vue web UI and dump-things API service to submit, edit, and review metadata records.
It applies to all record types, such as publications, personnel, projects, and topics.
For workflow-specific instructions (e.g., publication reporting), see the Workflows section.
The web UI for submitting, editing, and browsing records is provided at https://pool.v0.trr379.de/.

It is highly recommended to use this web UI with a desktop browser; the form offers rich contextual information that is hard to access on mobile devices.
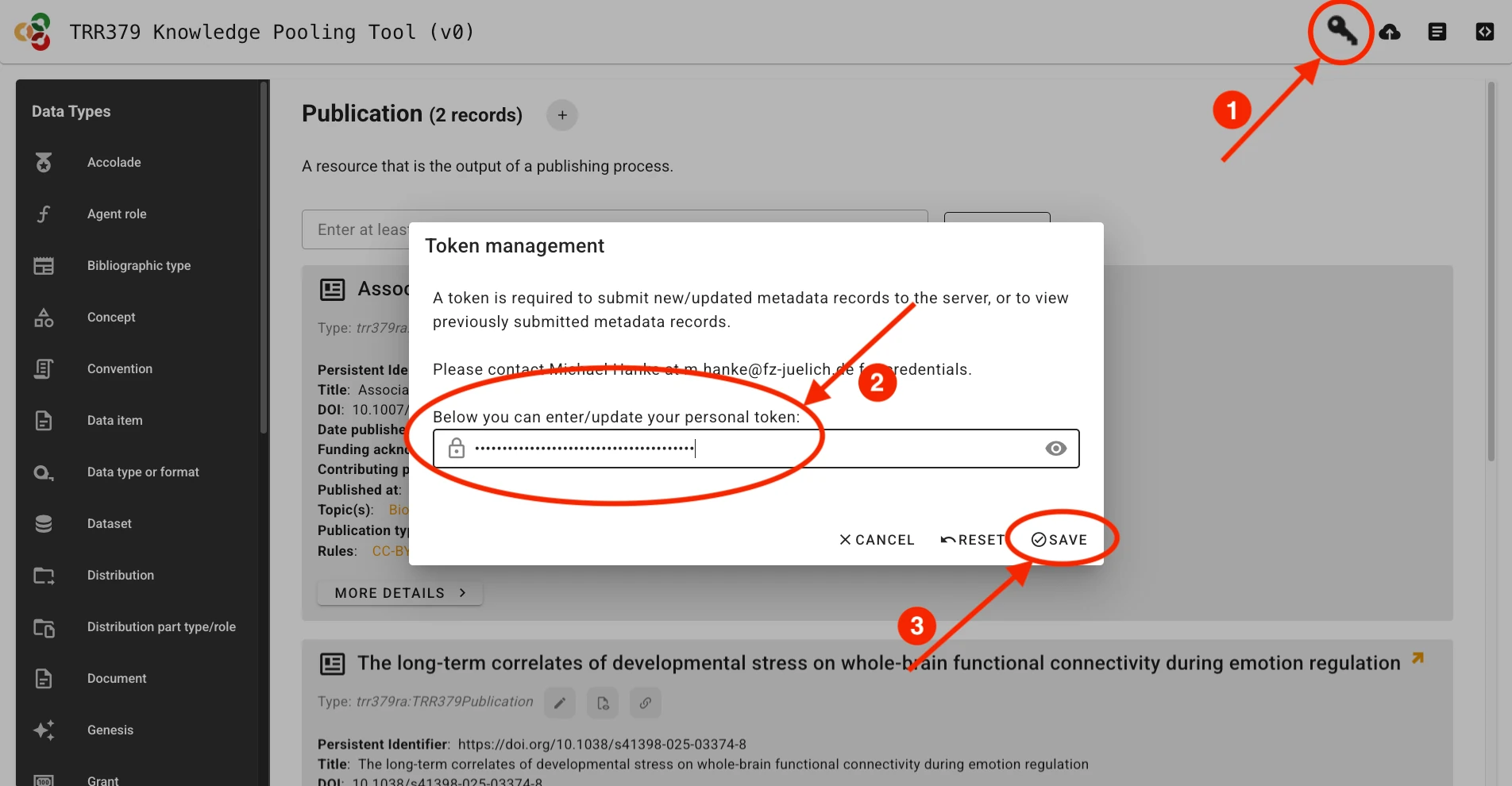
Submitting publication records will only be possible using a valid access token The token can be entered via the Key button in the web UI.
Records correspond to structured metadata entities (e.g., Person, Topic, Publication). Each record is created and managed through a form defined by the metadata schema.
If no record on a given entity already exists, a new record must be created.
Click the + (plus) button next to the desired record type (e.g., Publication or Person).
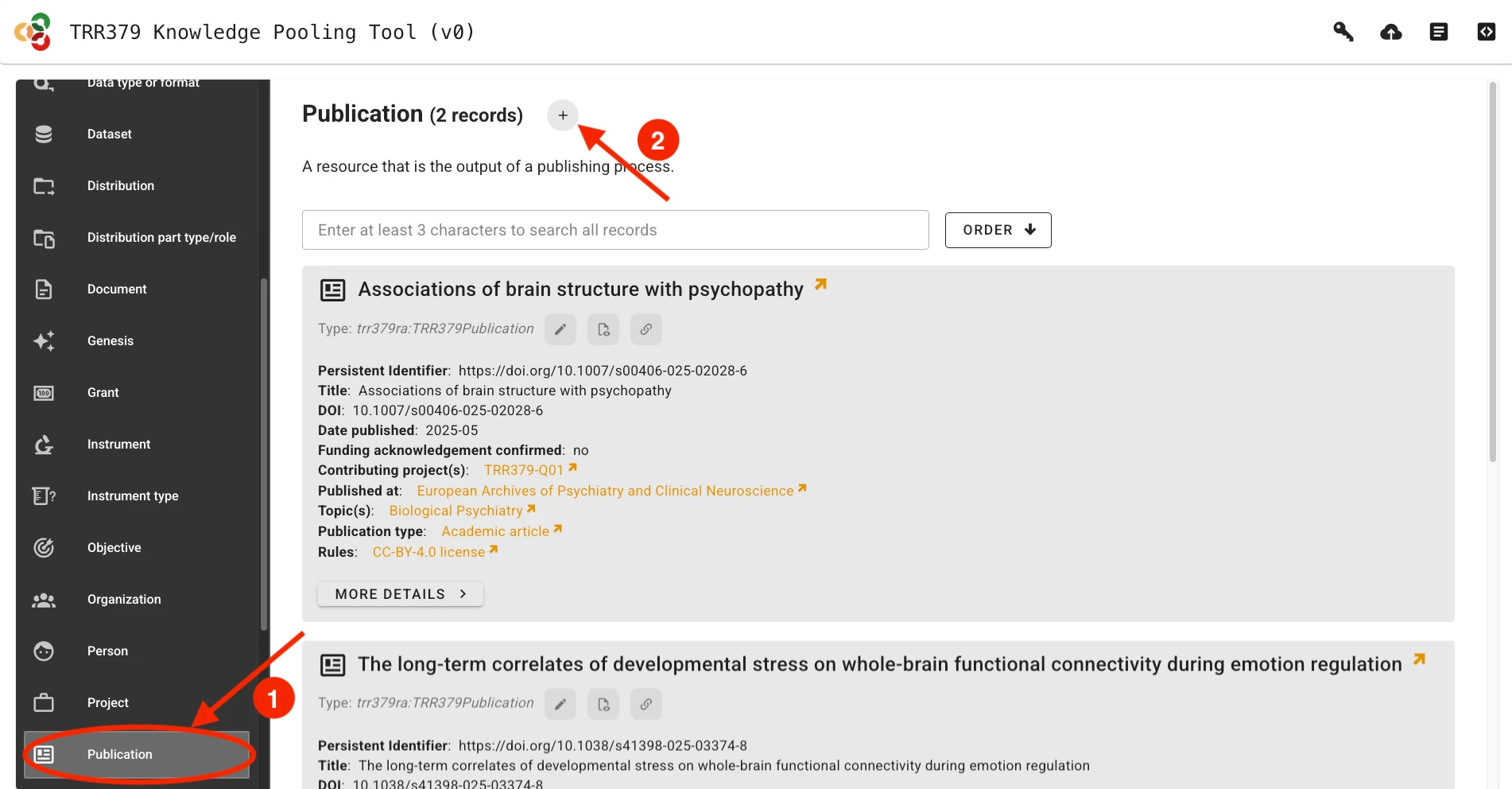
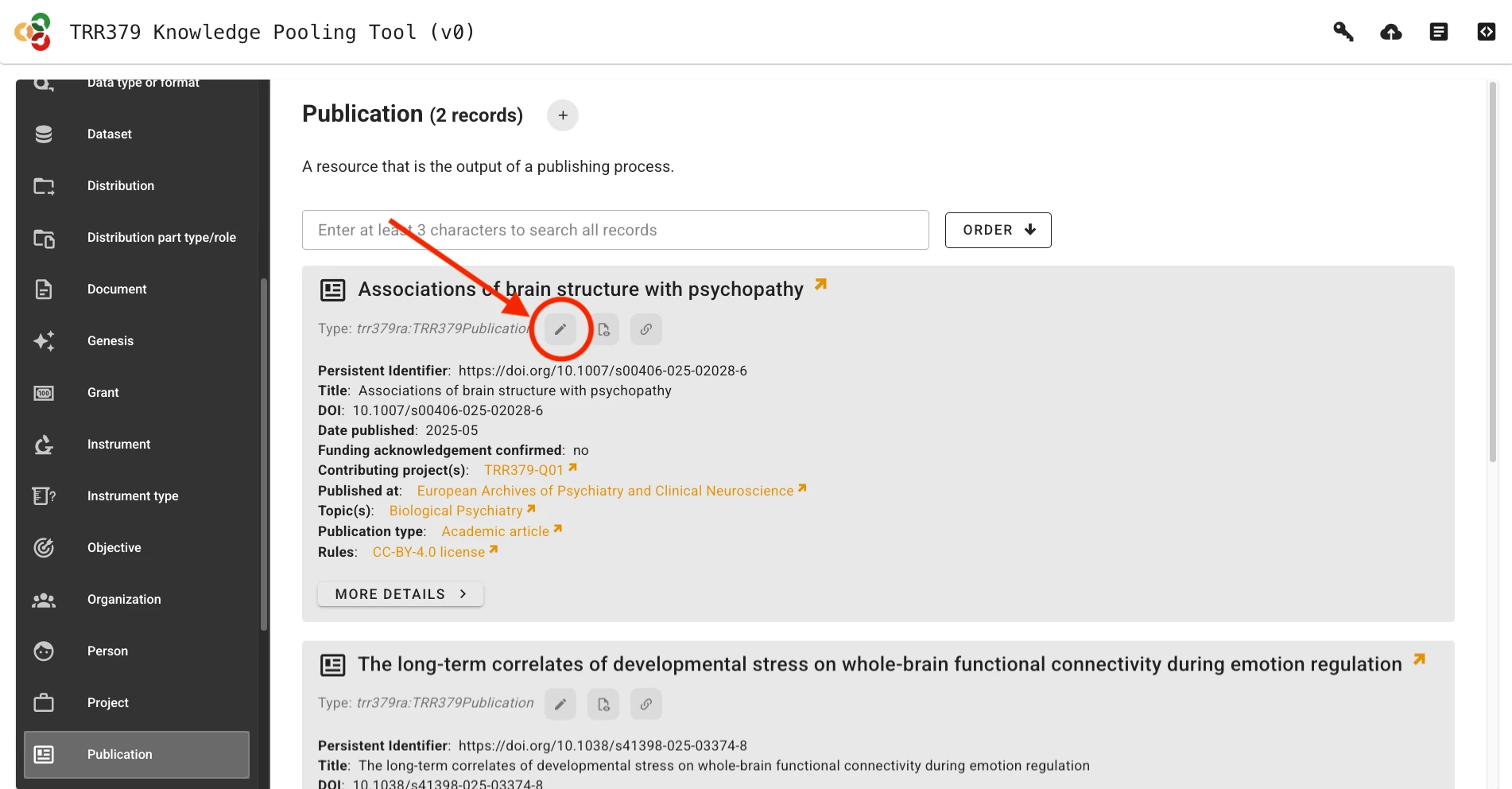
Alternatively, if a previous record already exists, it can be loaded by clicking on the Edit button (pencil icon). You can search for records by title/name, identifier, or other metadata attributes.
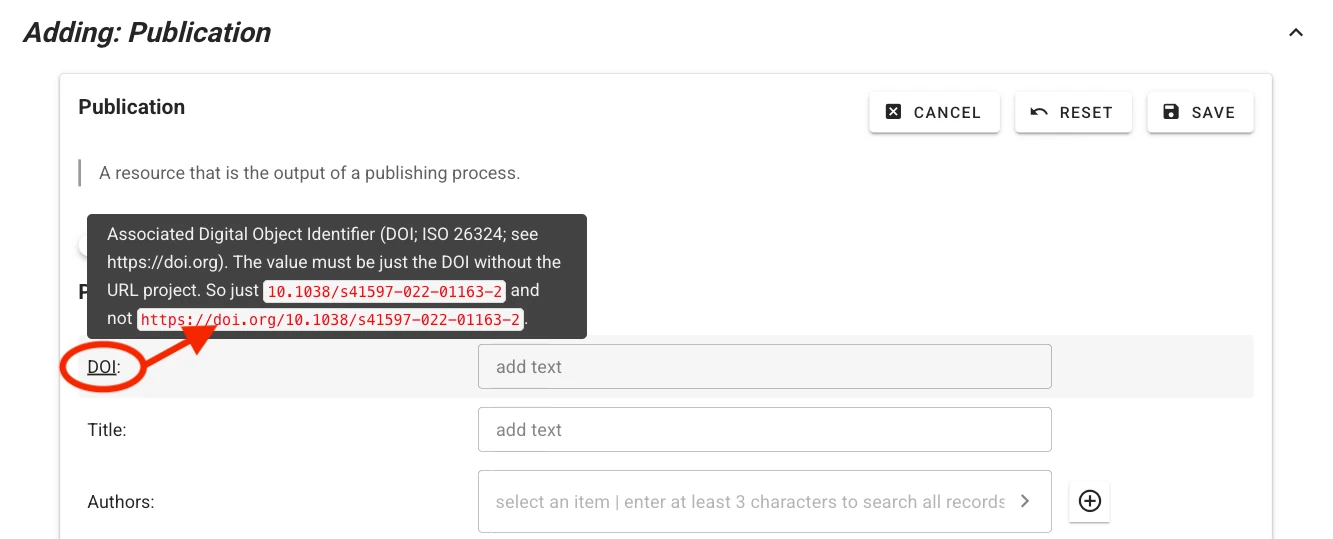
Context help describing expected values and controlled vocabularies is provided for each field. Hover your mouse pointer over the field label to display help text.
For some fields (e.g., authors or publication venue when filling out a publication record), one or more choices have to be selected. The selector offers type-ahead search of choices. The selection is contrained to choices matching the entered text in their label. Select the appropriate value from the dropdown list.
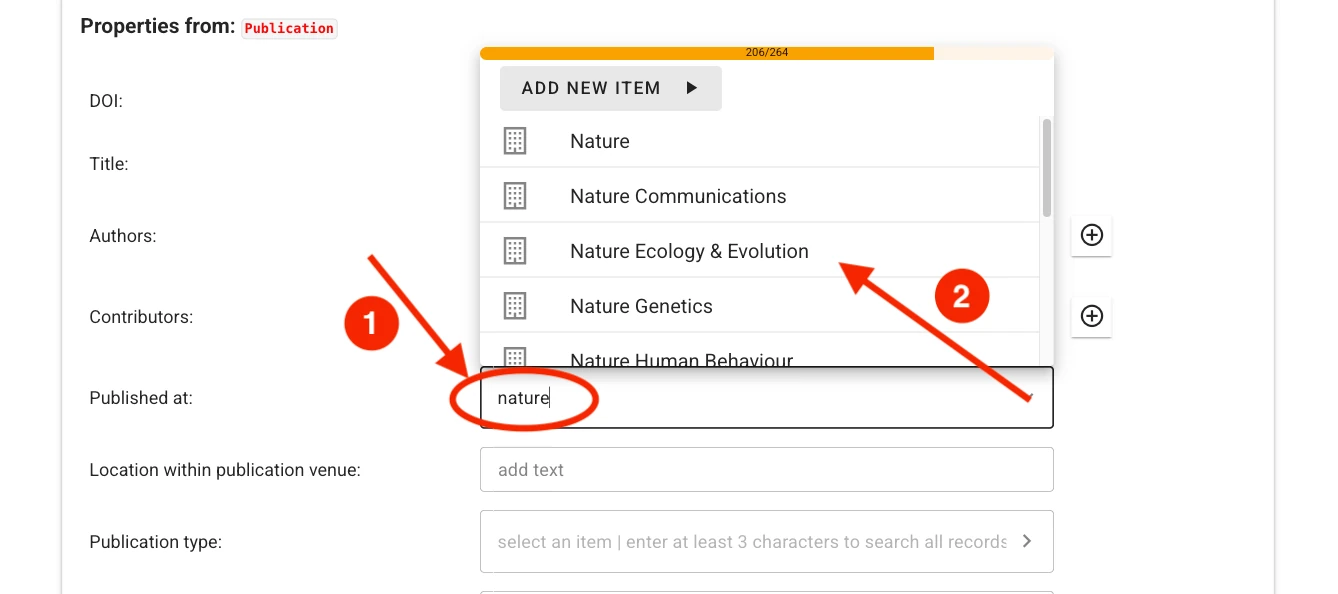
If no adequate choice exists, click Add New Item to create one.
Submitting metadata involves two different save actions: local saves and submitting to the server.
Saving only stores the information in the local browser session! It does not submit the record to the server to make it visible to curators.
Whenever a record (or sub-field) is completed, it must be saved by clicking the Save button. You must do this for each section you complete. Saving temporarily stores the record in your browser session.
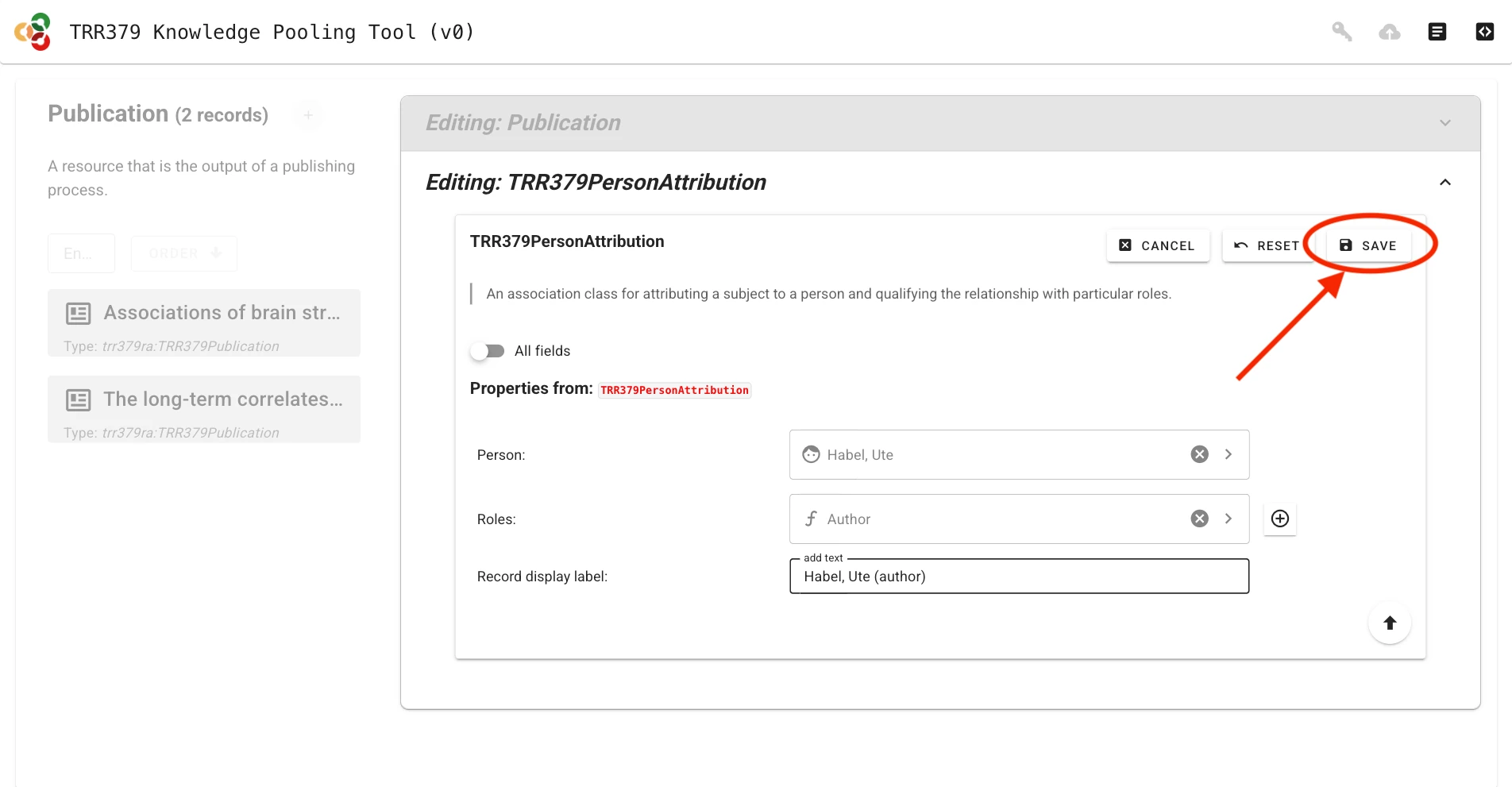
Once the record is complete and saved locally, it can be submitted to the server by clicking the Submit button (cloud icon with up arrow), which will show a green indicator if changes have not yet been submitted to the server. If you haven’t already entered your access token, the interface will prompt you to do so.
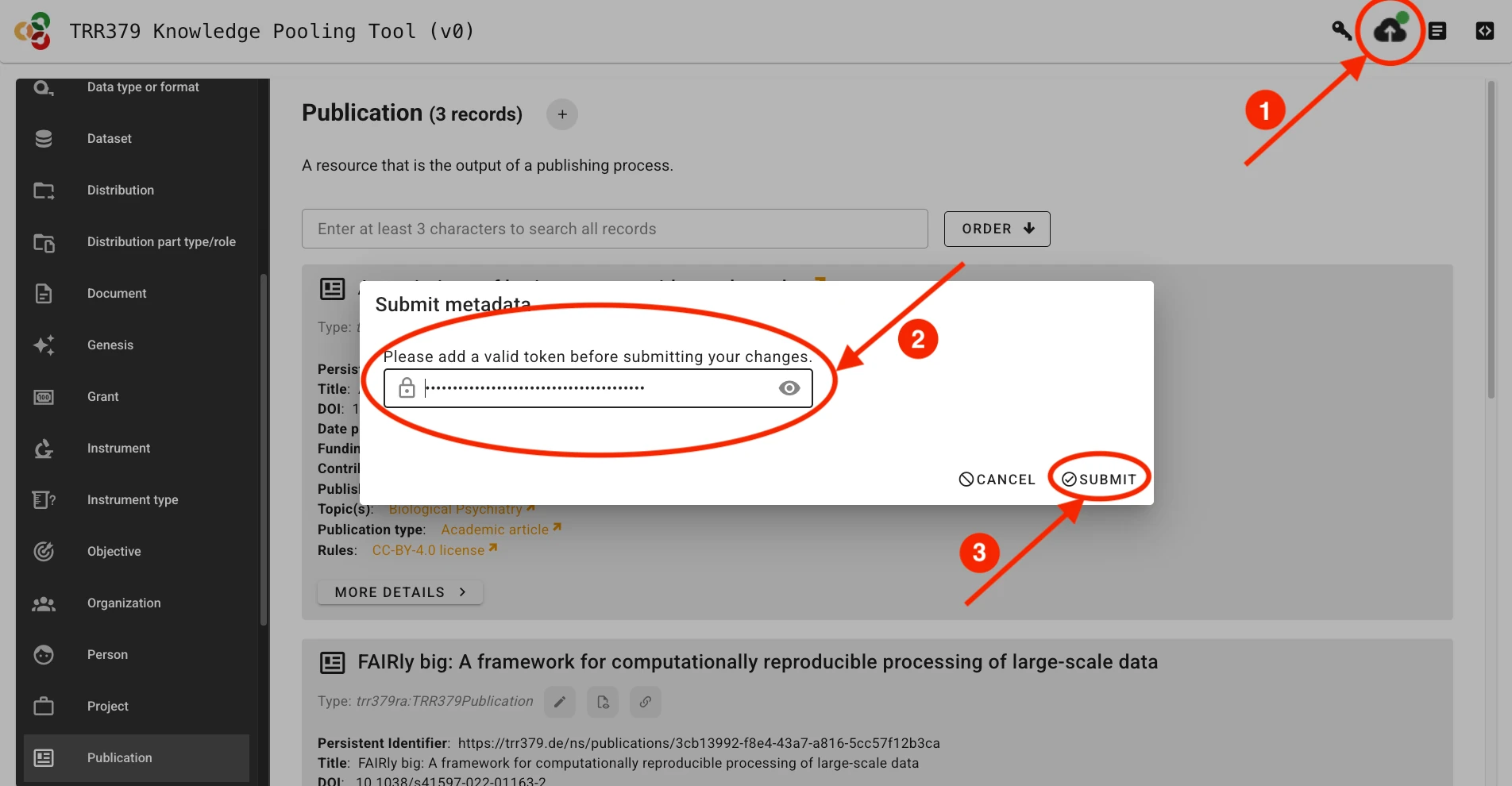
The interface will provide you with an overview of the changes you are about to submit.
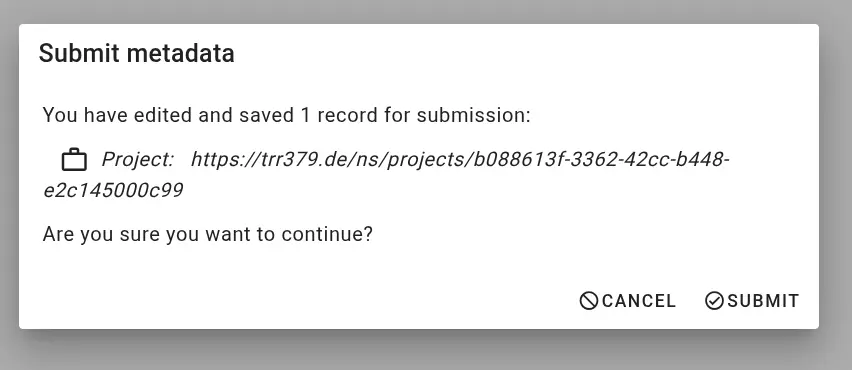
Authorization issues If the access token you are providing is incorrect or does not have appropriate permissions, the interface will display an error like this during metadata retrieval or submission:
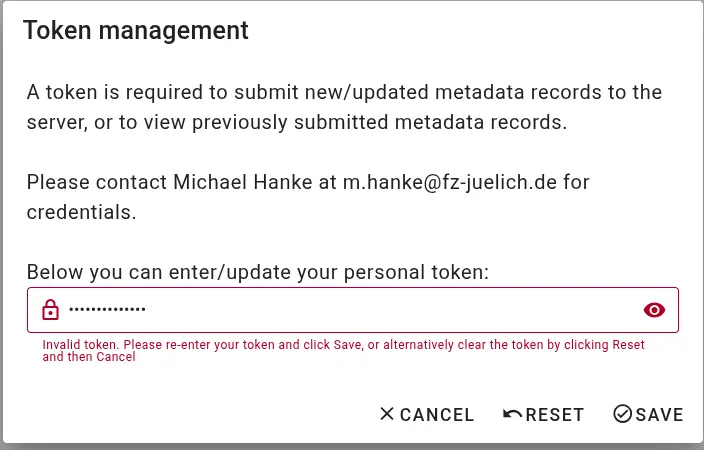
Incomplete information If a metadata record is missing required information, you will not be able to save it. Required fields - highlighted with a red asterix - and an warning sign will alert you to this.
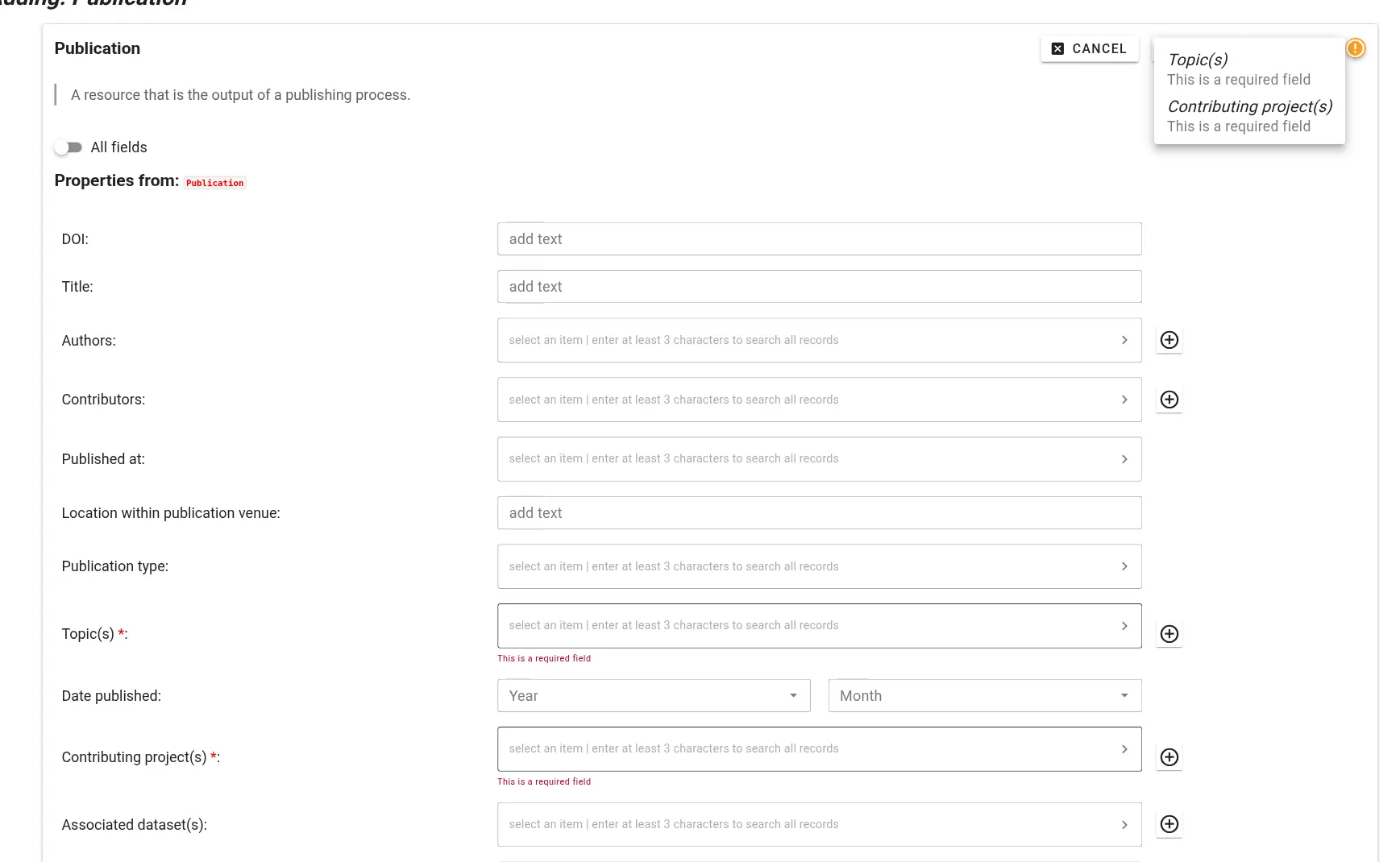
Internal errors If there is an unexpected error during metadata submission, the submission interface will report technical information. Please contact m.hanke@fz-juelich.de and copy the entire error message.
The TRR379 knowledge pooling tool supports several metadata-driven workflows to collect and curate research information. Each workflow describes how contributors can create, edit, and/or review records for a specific type of research output or activity.
Before starting a workflow, see the setup and general usage guides for instructions on accessing the tool and working with the web interface and backend API.
Use the links below to learn more about individual workflows:
The publication reporting workflow enables TRR379 members to register and curate metadata for publications associated with the consortium. This workflow ensures research outputs are accurately linked to relevant projects, topics, and contributors. Each submission includes contributor role assignments (e.g., author, senior author, etc.) to reflect the specific involvement of TRR379 members and collaborators.
In order to report a new publication, visit the knowledge pooling tool and select “Publication” as a data type from the left side of the page. Add a new publication by clicking the “plus” sign, or modify an existing record using its pencil icon.
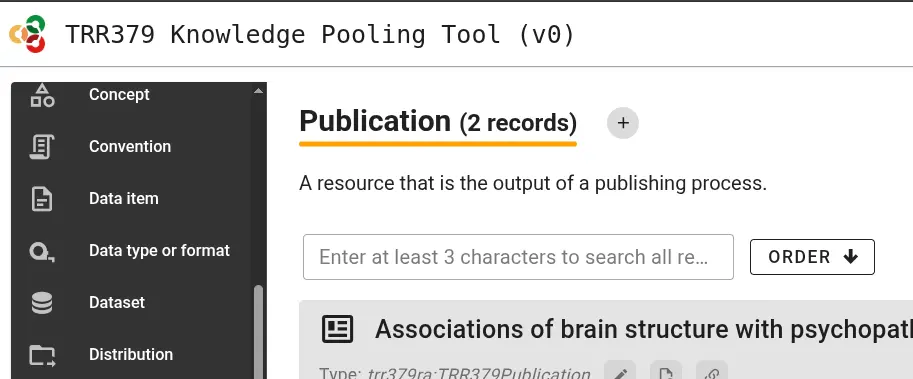
For publications to make the best impressions and live up to their fullest metadata potential, fill out the required and applicable optional fields. Where possible, the form lets you search through existing records, for example to easily link journals, authors, TRR topics, or projects.

For fine-grained information, also select the contribution role a given co-author played - for example corresponding author or data manager.

If non-TRR members authored or co-authored a publication, you can create new person records for these contributors. While TRR members can select trr-related prefixes for their persistent identifiers, external contributors can be identified persistently using, e.g., their ORCID.
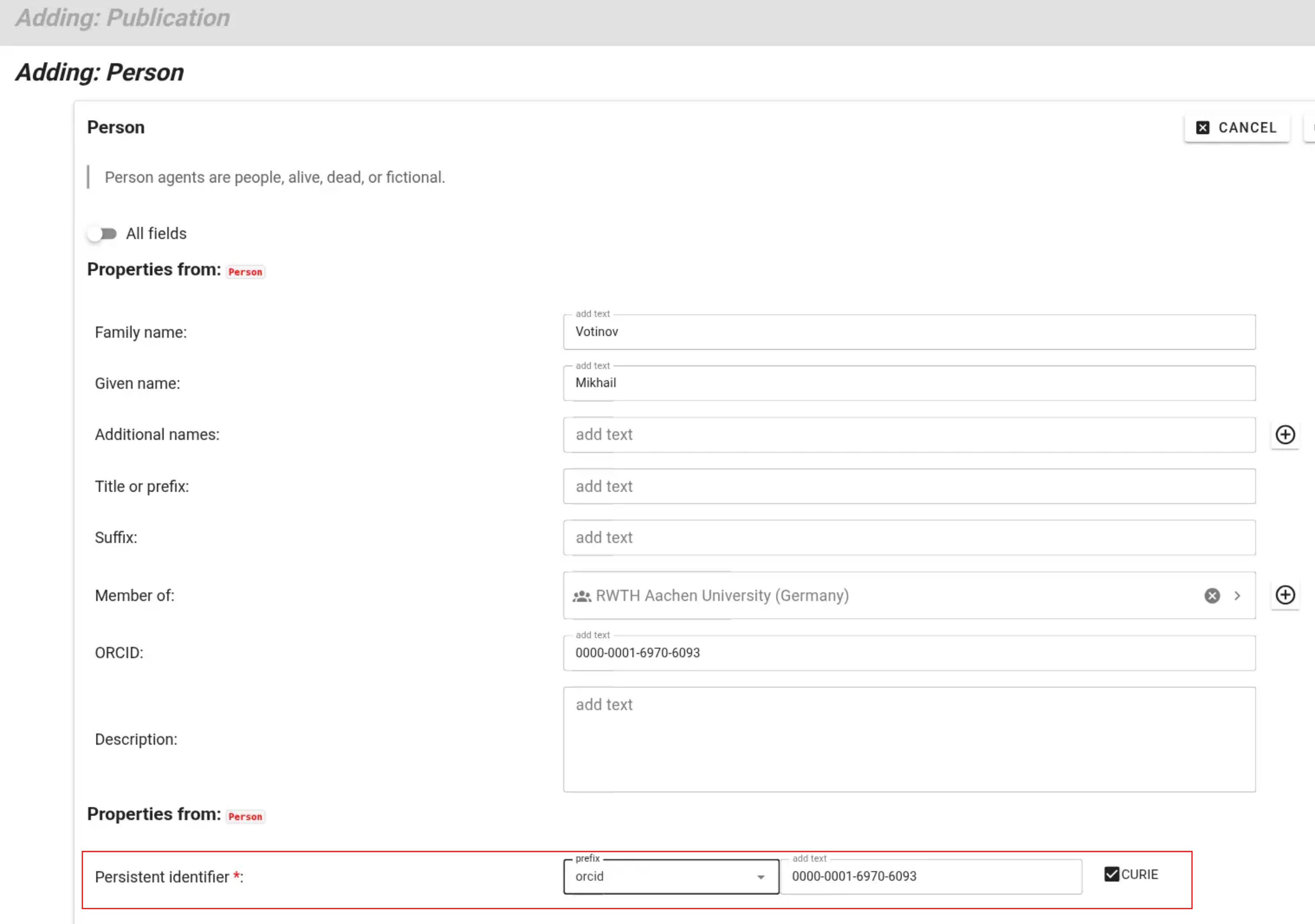
After saving, a well-curated publication record links to its authors, topics, and projects:

Finally, submit the added or edited records using the “submit” button.
Access the survey app to participate.
I am having issues with the survey form.
If there are issues with the form, they can be submitted on the TRR379 collaboration hub at https://hub.trr379.de/q02/dfg-cp-survey-ui/issues (requires an account), or emailed to trr379@lists.fz-juelich.de.
I need a personalized access token.
As a member of the TRR379, you should receive an individual access token via email. If you have not received one, please email Michael Hanke with a request.
The Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) gathers information from its funded projects on an annual basis. Some information is collected from all members of a coordinated programme, such as a collaborative research centre (CRC).
The data are used to produce statistical reports and provide answers to statistical queries. In addition, the data serve as the basis for statistical evaluations, which the DFG uses to comply with its reporting obligations to financial backers, the federal government and the state governments.
For more information, please refer to the information on data protection in relation to DFG research funding (see point 10 under Research Funding question IV), which can be accessed at https://www.dfg.de/privacy_policy.
The TRR379 collects the DFG survey data using the same infrastructure that is employed for research metadata collection and management, rather than the PDF-form based approach suggested by the DFG.
This offers the following advantages:
Collected information is submitted to a TRR379-dedicated virtual server hosted at Forschunsgzentrum Jülich (operated by the Q02 project) via an encrypted connection. Individual person records are only accessible via a personalized link with an individual access token. Members receive this access information via email.
This service is opt-in. Members who do not wish to have their data submitted and kept in the described way can follow the standard DFG-procedure and send the PDF-form available at https://www.dfg.de/resource/blob/203580/questionnaire-sfb-grk-fip-2025-en.pdf to the TRR379 management team.
The electronic survey form is provided at https://dfg-cp-survey.trr379.de
Members receive a personalized access link via email. Only with this link is it possible to see one’s personal record and to submit information.
It is highly recommended to use this webform with a desktop browser; the form offers rich contextual information that is hard to access on mobile devices.
If no record on a person already exists, a new record must be created.
This is done by clicking on the + button in the “Person” category.
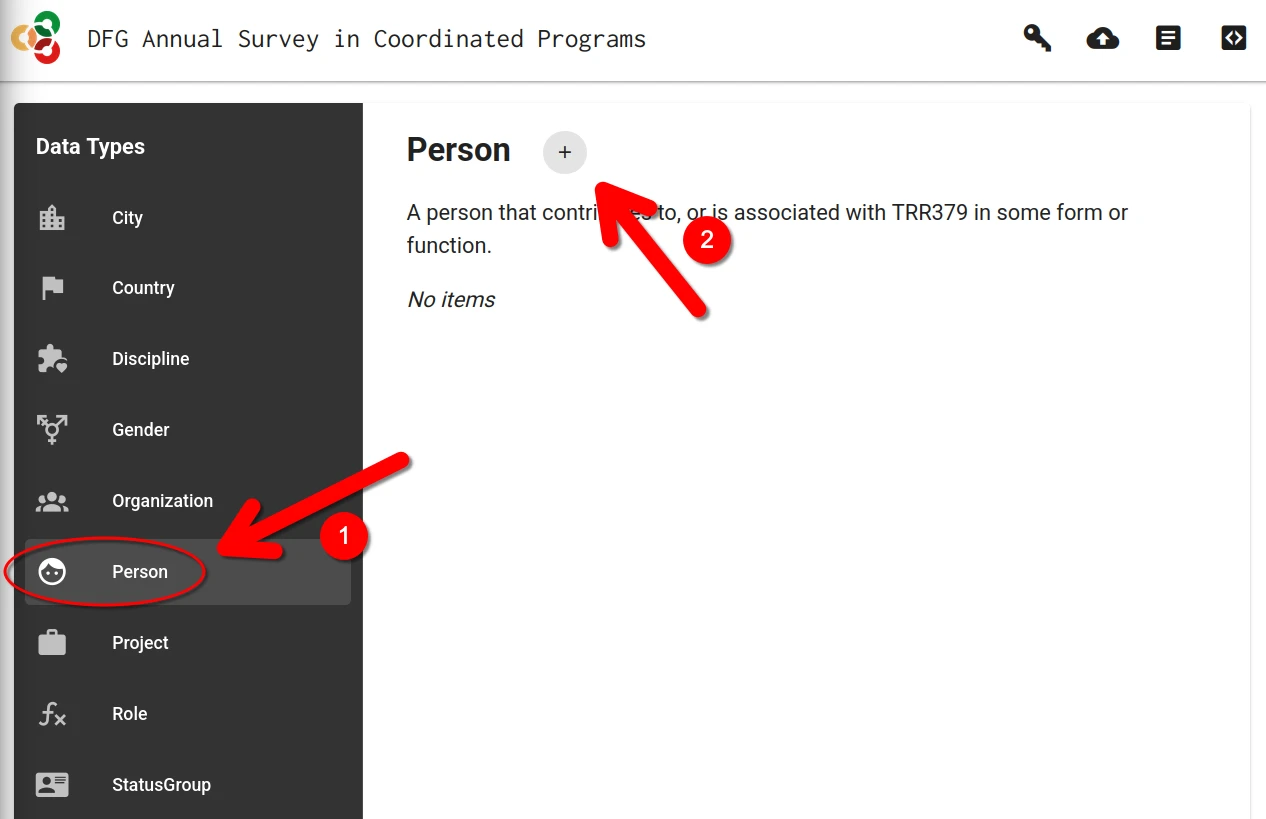
Alternatively, if a previous record already exist, it can be loaded by clicking on the “Edit” button (pencil icon).
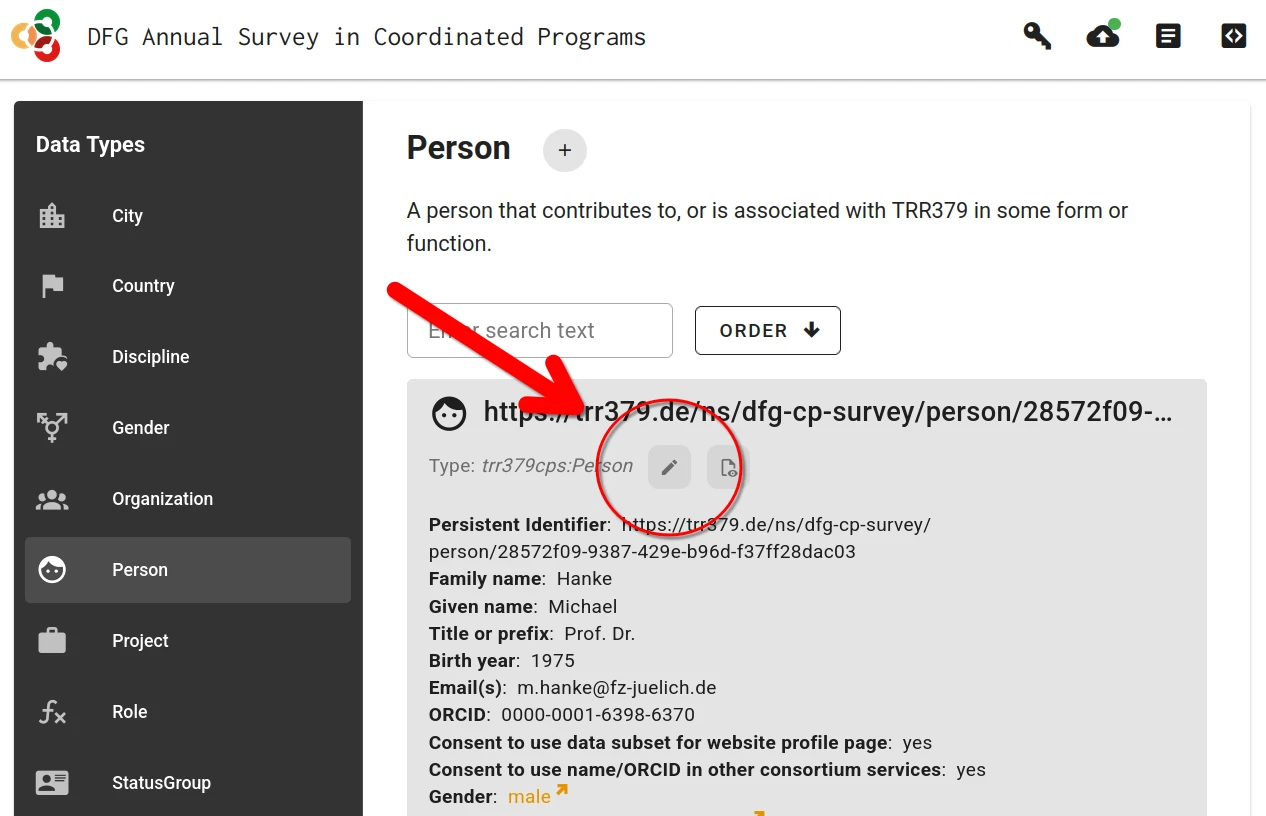
Context help is provided for every form filed. This information is accessible by hovering the mouse pointer over the field title.
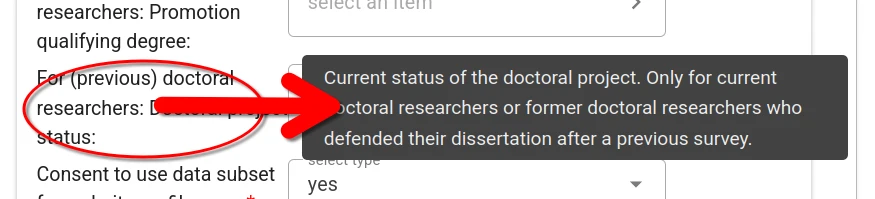
For some fields (e.g., prior workplace, area of study) one or more choices have to be selected. The selector offers type-ahead search of choices. The selection is constrained to choices matching the entered text in their label.
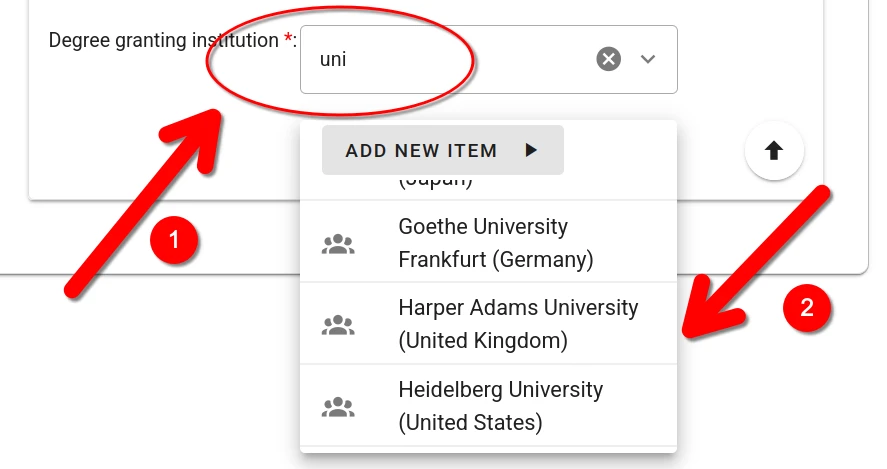
When no adequate choice exists, a new item can be created by clicking the “Add New Item” button.
There are two different save actions: local saves and submitting to the server.
Whenever a form (or sub-form) is completed, it must be saved by clicking the “Save” button. You must do this for each section you complete.
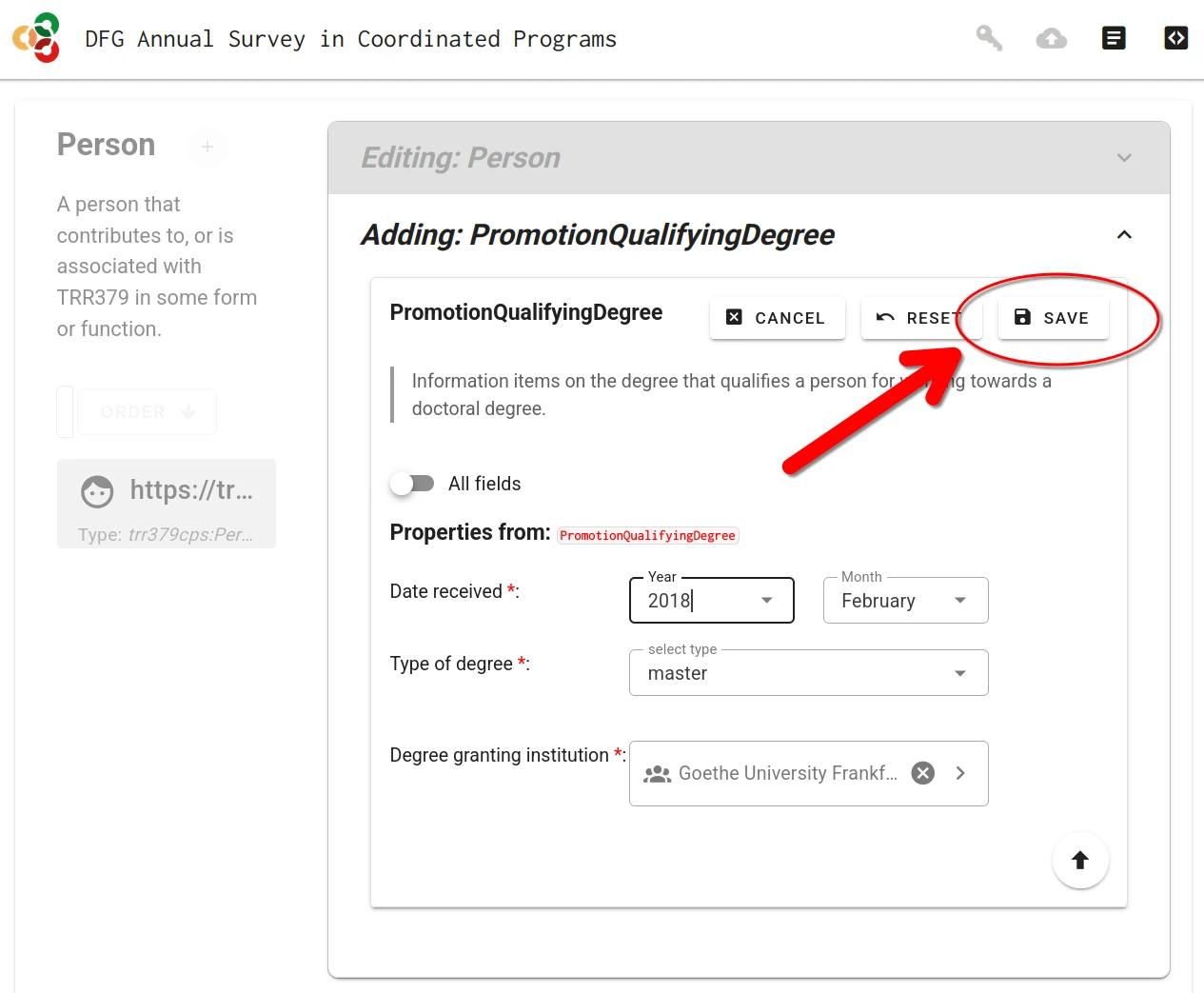
Saving only stores the information in the local browser session! It does not submit the form to the server.
When the person record is complete and is saved, the record can be submitted to the server by clicking the “Submit” button (cloud icon with up arrow).
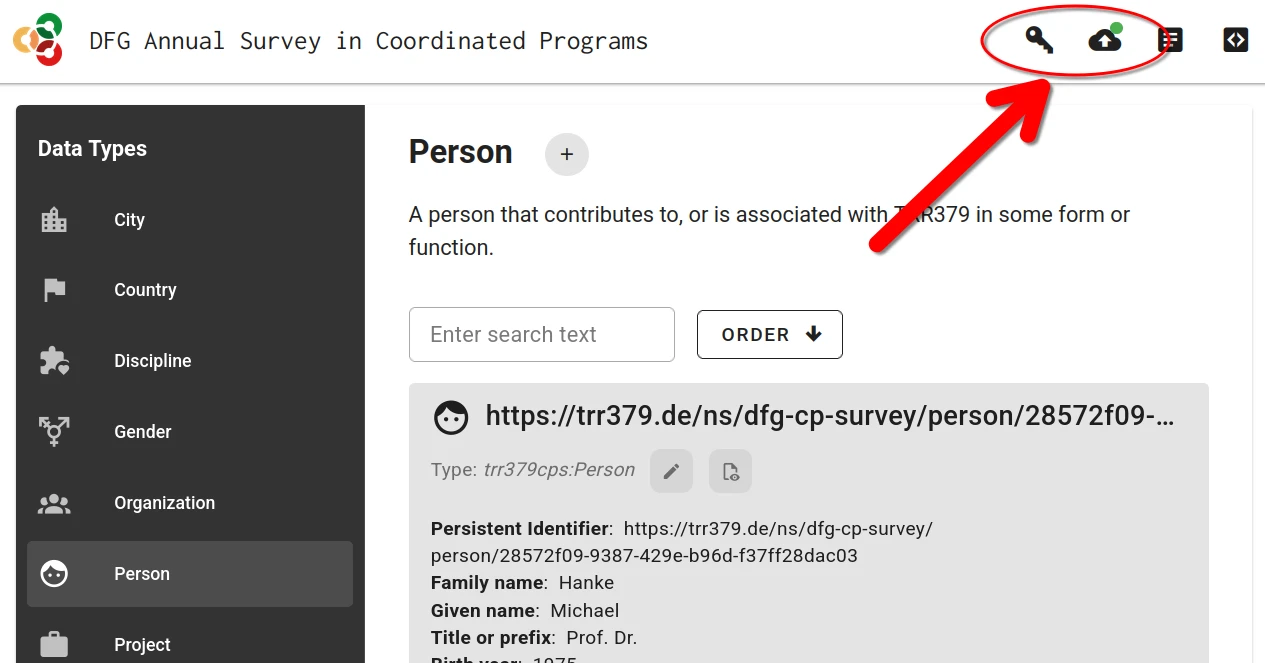
Submission is only possible with a valid access token. If the form was accessed via the personalized link, this token is already in place. If the form was accessed by other means, the token can be entered via the “Key” button. The token is embedded in the access link received via email.
The metadata service is a small application built on FastAPI that can be deployed running in a virtual environment, managed by Hatch – running under an unprivileged user account. This scenario is described here. However, any other deployment approaches suitable for Python-based applications may work just as fine.
The only software that is required outside the virtual environment (and the web server) is pipx, which is used to deploy hatch for a user – no need for administrator privileges otherwise.
Here we set up a dedicated user dumpthing to run the service.
However, the service could also run under any other (existing) user account.
Everything in this section is done under the target user account.
Use something like sudo -u dumpthing -s to enter it.
The following commands perform the initial setup, which provides an installation of the dump-things-service to query and encrich the TRR379 knowledge base.
If the service comes up with no error, we can ctrl-c it.
We use systemd for managing the service process, the launch, and logging.
This makes it largely unnecessary to interact with hatch directly, and allows for treating the user-space service like any other system service on the system.
The following service unit specification is all that is needed.
With this setup in place, we can control the service via systemd.
Here we use caddy as a reverse proxy to expose the services via https at metadata.trr379.de.
A matching DNS setup must be configured separately.
Afterwards we can reload the web server configuration and have it expose the service.
Whenever there are updates to the to-be-served curated metadata, the setup described here only required the equivalent of a git pull to fetch these updates from the “knowledge” repository.
When records are submitted, they end up in the directory matching the token that was used for submission.
Until such records are integrated with the curated metadata in global_store, they are only available for service requests that use that particular token.
An independent workflow must be used to perform this curation (acceptance, correction, rejection) of submitted records.
NeuroBagel is a collection of containerized services that can be deployed in a variety of way. This page describes a deployment using podman and podman-compose that is confirmed to be working on machine with a basic Debian 12 installation.
For other installation methods, please refer to the NeuroBagel documentation.
The following instruction set up a “full-stack” NeuroBagel deployment. The contains all relevant components
This setup is suitable for a self-contained deployment, such as the central TRR379 node. Other deployments may only need a subset of these services.
On the target machine, NeuroBagel services will run “rootless”. This means they operate under a dedicated user account with minimal privileges.
Only podman, and its compose feature are needed. They can be installed via the system package manager.
We create a dedicated user neurobagel on the target machine.
NeuroBagel will be deployed under this user account, and all software and data will be stored in its HOME directory.
In the HOME directory of the neurobagel user we create the complete runtime environment for the service.
All configuration is obtained from a Git repository.
NeuroBagel comprises a set of services that run on local ports that are routed to the respective containers.
Here we use caddy as a reverse proxy to expose the necessary services via https at their canonical locations.
A matching DNS setup must be configured separately.
We use systemd for managing the NeuroBagel service processes, the launch, and logging. This makes it largely unnecessary to interact with podman directly, and allows for treating the containerized NeuroBagel like any other system service.
The following service unit specification is all that is needed. With more recent versions of podman and podman-compose better setups are possible. using podman version. However, this one is working with the stock versions that come with Debian 12 (podman 4.3.1 and podman-composer 1.0.3) and requires no custom installations.
With this setup in place, we can launch NeuroBagel
Magnetic resonance imaging is an essential data acquisition method for TRR379. Four sites acquire such data. Each site has (different) established routines and conventions. This documentation collects resources and best practices that can be adopted by TRR379 members.
As the “true” raw data, DICOMs are rarely (re)accessed and hardly ever need to change. However, they need to be stored somewhere. Tracking DICOMs in DataLad datasets allows dependency tracking for conversion to NIfTI. However, it’s good to keep DataLad optional (allow DataLad and non-DataLad access).
The following solution has been proposed for the Imaging Core Facility at FZJ:
The system has been documented in https://inm-icf-utilities.readthedocs.io/en/latest/ and the tarball & dataset generation tools implementation is in https://github.com/psychoinformatics-de/inm-icf-utilities.
One of the TRR sites indicated intent to use a Forgejo instance for DICOM storage. A particular challenge for the underlying system was inode limitation. For this reason, an adaptation of the ICF system has been proposed:
A proof of principle for dataset generation (using re-written ICF code) has been proposed in https://hub.trr379.de/q02/dicom-utilities. See the README for more detailed explanations (and commit messages for even more detail).
Converting the heterogeneous, site-specific raw MRI data acquisitions into a standardized dataset is an essential precondition for the collaborative work in TRR379. It readies the data for processing with established pipelines, and applies a pseudonymization as a safeguard for responsible use of this personal data.
TRR379 uses the Brain Imaging Data Structure (BIDS) as the standard for its datasets.
The conversion of raw MRI data in DICOM format to a BIDS-compliant dataset is a largely automated process. The recommended software to be used for conversion is Heudiconv.
Heudiconv uses dcm2niix as the actual DICOM→NIfTI converter.
In our experience, dcm2niix is the most robust and most correct tool available for this task.
Heudiconv does the job of mapping DICOM series to BIDS entities (ie. determine BIDS-compliant file names). A key heudiconv concept is a heuristic: a Python program (function) which looks at the DICOM series properties and matches it with a file naming pattern. A heuristic typically relies on DICOM series naming (set at the scanner console), but it can also use other properties such as number of images or acquisition parameters.
Because TRR379 uses its own conventions, a matching heuristic needs to be provided (possibly one for each TRR379 site). An implementation of such a heuristic has been created, and was tested on phantom MRI acquisitions from all sites (see below). Using this heuristic, MRI data from all sites can be BIDS-standardized. As with any automation, caution and oversight is needed for edge cases (e.g. repeated / discarded acquisitions).
Heudiconv tutorials further illustrate the process and capabilities of the software.
Scans of MRI phantoms were carried out using the intended sequences (presumably - see caveats section below). These were shared with Q02 and uploaded to the TRR Hub forgejo instance:
Note: Aachen did a re-scan which was shared by e-mail / cloud (June 03, 2025). This has not been uploaded to forgejo (permissions + size).
Conversion of re-scanned Aachen phantom is in https://hub.trr379.de/q02/tmp-phantom-bids (separate from the above because input data is not available as a DataLad dataset)
These are open questions:
Identifiers are an essential component of the TRR379 research data management (RDM) approach. This is reflected in the visible organization of information on the consortium website, but also in the schemas that define the structure of metadata on TRR379 outputs.
Many systems for identifying particular types of entities have been developed. A well-known example is DOI for digital objects, most commonly used for publications. However, many others exist, like ROR for research organizations, or Cognitive Atlas for concepts, tasks, and phenotypes related to human cognition.
RDM in the TRR379 aims to employ and align with existing systems as much as possible to maximize interoperability with other efforts and solutions. However, no particular identifier system is required or exclusively adopted by TRR379.
Instead, anything and everything that is relevant for TRR379 has an identifier in a TRR379-specific namespace.
TRR379 RDM heavily relies on persistent identifiers. More or less anything and everything has, and must have, a persistent identifier. This key constraint makes it possible for multiple actors to collaboratively, and simultaneously contribute metadata on arbitrary aspects – without having to wait and query for finished metadata records on associated entities.
TRR379 uses URIs as identifiers that map onto the structure of the main consortium website.
For example, the full TRR379 identifier for the spokesperson Ute Habel is https://trr379.de/contributors/ute-habel.
In this URI, https://trr379.de is the unique TRR379-specific namespace prefix, contributors/ute-habel is the TRR379-specific identifier for Ute Habel (where contributors is a sub-namespace for agents that in some way contribute to the consortium).
Even though Ute Habel can also identified by the ORCID
0000-0003-0703-7722, via the quasi-standard identifier system for researchers, this alternative identifier is considered an optional, alternative identifier rather than a requirement for TRR379 RDM.
The reasons for this approach are simplicity, and flexibility.
An identifier in TRR379 RDM is a simple text label, in a self-managed namespace. This self-managed namespace can cover any and all entity types that require identification with TRR379. In many cases, an identifier directly maps to a page on the main consortium website. This is a simple strategy to document the nature of any entity. It also establishes the main website as a central, straightforward instrument for communicating and deduplicating identifiers in a distributed research consortium.
Even though any relevant entity can receive a TRR379-specific identifier with the approach described above, the utility of these identifier is limited to TRR379-specific procedures and activities. However, a TRR379 metadata record on a research site (e.g., https://trr379.de/sites/aachen ) can be annotated with any alternative identifier for the same entity (e.g., https://ror.org/04xfq0f34 ). Thereby it is possible to combine the benefits of a self-governed, project-specific identifier namespace with the superior discoverability and interoperability of established identification systems for particular entities.
The additional documentation linked below provides more information on particular identifiers used by TRR379.
This page is a more in-depth description of the rationale behind the SOP for participant identifiers used by TRR379.
Q01 is the central recruitment project. Any participant included in the core TRR379 dataset is registered with Q01 and receives an identifier. This identifier is unique within TRR379 and stable across the entire lifespan of TRR379.
The dataset acquired by TRR379 is longitudinal in nature. Therefore participants need to be reliably identified and re-identified for follow-up visits. Because participants are not expected to remember their TRR379 identifier, it is necessary to store personal data on a participant for the time of their participation in data acquisition activities.
In order to avoid needlessly wide-spread distribution of this personal data, participant registration and personal data retention is done only at the site where a person participates in TRR379 data acquisitions. Each site:
The site-issued identifiers have a unique, site-specific prefix (e.g., a letter like A for Aachen), such that each site can self-organize their own identifier namespace without having to synchronize with all other sites to avoid duplication.
The identifiers must not have any other information encoded in them.
The TRR379 participant identifiers, as described above, are pseudonymous. Using these TRR379-specific identifiers only, for any TRR379-specific communication and implementations, is advised for compliance with the GDPR principles of necessity and proportionality of personal data handling. This includes, for example, data analysis scripts that can be expected to become part of a more widely accessible documentation or publication.
Any TRR379 site that issues identifiers is responsible for strictly separating personal data used for (re-)identifying a participant, such as health insurance ID, government ID card numbers, or name and date of birth. This information is linked to TRR379-specific identifiers in a dedicated mapping table. Access to this table is limited to specifically authorized personnel.
When a participant withdraws, or when a study’s data acquisition is completed, the mapping of the TRR379 identifier to personal identifying information (1) is destroyed, by removing the associated record (row) from the mapping table. At this point, the TRR379 identifier itself can be considered anonymous. Consequently, occurrences of such identifiers in any published or otherwise shared records, or computer scripts need not be redacted.
The validity of the statement above critically depends on the identifier-issuing sites to maintain a strictly separate, confidential mapping of identifier to personal identifying information, and to not encode participant-specific information into the identifier itself.
For each project or study that is covered by its own ethics documentation and approval, separate and dedicated participant identifiers are used that are different from a Q01-identifier for a person. This is done to enable such projects to fulfill their individual requirements regarding responsible use of personal data. In particular, it enables any individual project to share and publish data without enabling trivial, undesired, and unauthorized cross-referencing of data on an individual person, acquired in different studies.
These project-specific identifiers are managed and issued in the same way as described above.
Importantly, the mapping of the Q01-identifier and a project-specific identifier is typically not shared with the requesting project. This is done to prevent accidental and undesired co-occurrence of the two different identifiers in a way that enables unauthorized agents to reconstruct an identifier mapping that violates the boundaries of specific research ethics.
Sometimes it is necessary to generate participant identifiers that are not compliant with the procedures and properties described above. For example, an external service provide may require particular information to be encoded in an identifier (e.g., sex, age, date of acquisition).
If this is the case, an additional identifier must be generated for that specific purpose. Its use must be limited in time and it must not be reused for other purposes.
Identifier generation and linkage to the standard Q01-participant identifiers is done using the procedure described for project-specific identifiers above.
[This is a draft under discussion]
The planned RDM infrastructure is a federation of interoperable site infrastructures. The key design principle is that no primary data are aggregated to a central infrastructure.
We aim to establish an infrastructure that is suitable for use within the TRR379, but not limited to this scope. Once deployed, the associated services are usable beyond the scope of TRR379.
The following schema sketches the planned infrastructure. Components that hold (primary) data are depicted in yellow. Components that hold (mostly or exclusively) metadata are shown in blue. The direction of information flow is indicated by arrows, exchange of data by solid arrows, and metadata-only exchange by dotted arrows. Infrastructures that are only accessible to authorized agents are labeled with a “lock” symbol. Further details on individual components are provided below.
graph TB;
subgraph Central services
C1[("Collaboration portal<br>hub.trr379.de<br> 🔐")]:::meta
C2{{"Data search<br>query.trr379.de<br> 🔐"}}:::meta
C3(Main website<br>www.trr379.de):::meta
C4("Data catalog<br>data.trr379.de"):::meta
end
subgraph "Aachen 🔐"
A1[(hub)]:::data
A1a[(lab1)]:::data
A1b[(lab2)]:::data
A2{{query}}:::meta
end
subgraph "Frankfurt 🔐"
F1[(hub)]:::data
F2{{query}}:::meta
end
subgraph "Heidelberg 🔐"
H1[(hub)]:::data
H1a[(ZI-hub)]:::data
H1b[(lab1)]:::data
H2{{query}}:::meta
end
A1 -.-> C1
A1a -.-> A1
A1b <---> A1
A1 -.-> A2
A2 <-.-> C2
F1 -.-> C1
F2 <-.-> C2
F1 -.-> F2
C3 <-.-> C1
C3 -.-> C2
H1 -.-> C1
H1a <-.-> C1
H1a <-.-> H1
H1b <---> H1
H1 -.-> H2
H2 <-.-> C2
C1 -.-> C2
C1 -.-> C4
C3 -.-> C4
H1b <---> A1a
%% node links to actual services
click C1 href "https://hub.trr379.de"
click C3 href "https://www.trr379.de"
%% classes to distinguish data and metadata nodes
classDef data fill:#ffa200,color:#000
classDef meta fill:#5C99C8,color:#000
%% invisible link purely for manipulating the grouping
C2 ~~~ A1b
C4 ~~~ A1b
C2 ~~~ F1
C2 ~~~ H1b
All central services a metadata-focused. No primary data acquired at participating sites are aggregated into central databases/storage.
This is the main hub for collecting actionable links to all TRR379 resources and information. The software solution for this hub is Forgejo-ankesajo. It is a free and open-source software package, and the direct service counterpart of DataLad, the main tool proposed for implementing reproducible research workflows in TRR379 labs.
The hub will store DataLad datasets, referencing all TRR379 data resources without hosting any actual data. Instead the DataLad dataset point to the individual institutional data stores, or to community data repositories when and where data have been published.
The hub is also a place to deposit (shared) computational environments, and implementations of (shared) data processing pipelines, software publications, and source code repositories under a uniform TRR379 umbrella.
A test site is deployed at https://hub.trr379.de and is being evaluated.
See this page for a description of the main website. Importantly, the website renders essential metadata for the TRR379 (contributors, roles, publications, projects, research topics, etc.) It provides a unique URI for any such entity, to be used as identifiers in all TRR379 (meta)data resources.
The website is programmatically generated from a repository hosted on the TRR379 hub, to enable contributions by all TRR379 members.
The TRR379 data catalog is a website dedicated to providing a uniform (read-only) view on the TRR’s data resources. It is rendered programmatically by DataLad Catalog from metadata on TRR379 data resources hosts in the TRR379 hub.
This site is indexed by specialized search engines like Google’s dataset search and a key enabler for general findability of TRR379 resources.
This is a federated data discovery service that is tailored to the cohort dataset acquired by TRR379 as a whole. It will enable the discovery of individual data records matching a given set of criteria, regardless of the contributing TRR379 site.
The service is federated. Each sites runs their own instance, and has the sole authority on deciding what metadata are shared with other TRR379 sites. Only these metadata property will be accessible by TRR379 at large, while more detailed metadata records can be use for in-house queries.
The proposed solution for the query service is a version of NeuroBagel adapted to the data nature and needs of TRR379.
Sites are free to implement any RDM solutions, as long as that infrastructure provides
with the aim to enable reproducible research from primary data to published results within and across TRR379.
Q02 supports sites with software solution that facilitate interoperability within TRR379. This includes the local deployment of the software systems used to run the central services.
We aim at individual sites running their own data hubs (using the same software solution) as the central https://hub.trr379.de. In contrast to the central hub, these institutional sites can directly use the storage features of Forgejo-ankesajo, and host arbitrary amounts of data. TRR379 can communicate data availability using a federation protocol.
A collaborative research centre (CRC) is a DFG funded long-term university-based research institution, established for up to 12 years, in which researchers work together within a multidisciplinary research programme. Collaborative Research Centres consist of a large number of projects. The number and scope of these projects depend on the research programme. Individual projects are led by one researcher or jointly by several researchers.
The German Research Foundation (Deutsche Forschungsgemeinschaft, DFG) is a German research funding organization.
A standard operating procedure, mostly referred to as SOP, is a set of step-by-step instructions compiled to help carry out routine operations.
A Transregio (TRR) is a variant of a DFG funded Collaborative Research Centre. Whereas traditional collaborative research centres are proposed and carried out by one university, a CRC is proposed and carried out jointly by two or three universities. It allows close cooperation between these institutions and the researchers based there, including the shared use of resources. The contributions of the partner applicants are essential to the joint research goal, complementary and synergistic.